Programming
Posts tagged with "Programming"
Hey, I made a thing
I just published my very first Chrome Extension to the Google Play Store! It's actually not hard at all, and I'm going to come back here and beef up this post with more of the details when I have some more time. But in a nutshell, if you use Atlassian's Bitbucket service, you might be familiar with "pull requests," otherwise known as code reviews. These are immensely helpful, but sorely lacking one critical feature: there's no way to easily expand/collapse whole sections of a pull request. So, I added that feature! But I did so in a really lazy way. Rather than taking the time to figure out how to hook into the loaded events, I just a gigantic button on top that says "Active Toggle." Click that button once all the files have been loaded up, and it will then add individual "Toggle" buttons to each section. Enjoy!
https://chrome.google.com/webstore/detail/bitbucket-pull-request-to/hfebajohpclnfhfnlhgndbmcdnlchjjd
How to do Joins in MongoDB
If you've come here looking how to perform a JOIN operation on two or more collections in MongoDB, you've come to the wrong place. In fact, that is exactly what I'm about to show you how to do, but trust me, you shouldn't be doing it. If you're trying to do that, that's a clear indication that you have relational data. And if you have relational data, that means you've made the wrong choice for your database. Don't use Mongo; use a relational database instead. I know it's cool and shiny and new, but that is not a good rationale to use it. SQL is your best bet. I'd recommend you read Why You Should Never Use MongoDB by Sarah Mei. Now, with that disclaimer out of the way, I'll dive right into it.
We've been using MongoDB for some of our data storage at work. The choice to use Mongo was a decision made well before I arrived, and incidentally, we might be changing that out at some point in the future. But nevertheless, as it's the system currently in place, I've had to work within that system.
There were a number of pre-established Mongo queries in the codebase I've been working on, and I'm sorry to say many of them were really quite slow. So over the course of a weekend, I tried out a couple of ideas that seemed intuitive enough and managed to speed up some of these common queries by an order of magnitude. The queries I'm talking about grabbed data from multiple collections simultaneously, hence why they were initially so slow, and hence the title of this blog post. In this post I'm going to dissect a number of the techniques I used to speed up these Mongo queries, with plenty of code examples along the way.
Let's say you've got a collection in Mongo called Transactions. This table has a variety of fields on each row, including one field called userId, which is just the ObjectID (aka foreign key, for you SQL folks) of a document in the separate Users collection. You might want to retrieve a list of transactions in a given time period, and show some information on the screen, like the date, the total amount, and the first and last name of that user. But for this first part, let's hold off on any attempts at JOINs, and just look at accessing the Transactions collection alone.
I ran some benchmarks with the following code on my local machine, which was also running a local instance of MongoDB.
MongoClient conn = new MongoClient(new ServerAddress("127.0.0.1", 27017));
DB db = conn.getDB("MyDatabase");
DBCollection transactions = db.getCollection("Transactions");
SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = f.parse("2014-06-01");
DBObject gt = new BasicDBObject("$gt", startDate);
DBObject match = new BasicDBObject("created", gt);
Cursor cursor = transactions.find(match);
List<Map> rows = new ArrayList<>();
while ( cursor.hasNext() ) {
Map<String, Object> row = new HashMap<>();
DBObject dbObject = cursor.next();
row.put("total", dbObject.get("total"));
row.put("approved", dbObject.get("approved"));
row.put("canceled", dbObject.get("total"));
row.put("location", dbObject.get("canceled"));
row.put("items", dbObject.get("items"));
row.put("coupons", dbObject.get("coupons"));
row.put("created", dbObject.get("created"));
row.put("updated", dbObject.get("updated"));
row.put("deleted", dbObject.get("deleted"));
row.put("userId", dbObject.get("userId"));
rows.add(row);
}$conn = new Mongo('mongodb://localhost:27017');
$db = $conn->selectDB('MyDatabase');
$transactions = $db->selectCollection('Transactions');
$match = array(
'created' => array('$gt' =>
new MongoDate(strtotime('2014-06-01'))
));
$cursor = $transactions->find($match);
$rows = array();
while ( $cursor->hasNext() ) {
$dbObject = $cursor->getNext();
$rows[] = array(
'total' => $dbObject['total'],
'approved' => $dbObject['approved'],
'canceled' => $dbObject['canceled'],
'location' => $dbObject['location'],
'items' => $dbObject['items'],
'coupons' => $dbObject['coupons'],
'created' => $dbObject['created'],
'updated' => $dbObject['updated'],
'deleted' => $dbObject['deleted'],
'userId' => $dbObject['userId']
);
}This code is obviously sanitized a bit here to highlight what I'm doing, but you might extend this to do any number of things. You might have some sort of POJO that corresponds to a single document in the collection, and instantiate a new one within each loop. Then you would call dbObject.get() to retrieve each of the properties of that row. I iterated this simple test hundreds of times on my local machine, and found, on average, it took 0.663 seconds to complete. And in case you're curious, the date range I've given here corresponds to roughly 30,000 documents. So that's not so bad.
But this pared-down example was not my use case, and my use case was performing poorly. So I thought, well, I don't need all those pieces of data in the dbObject. I really only needed two. So I formulated a hypothesis. My hypothesis was simple: if I only grab the data I need, and none of the data I don't, the query would perform better. This is akin to avoiding SELECT * in SQL (which is something you should always avoid). So to start, I made the most basic modification to the code possible, which you can see here:
SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = f.parse("2014-06-01");
DBObject gt = new BasicDBObject("$gt", startDate);
DBObject match = new BasicDBObject("created", gt);
Cursor cursor = transactions.find(match);
List<Map> rows = new ArrayList<>();
while ( cursor.hasNext() ) {
Map<String, Object> row = new HashMap<>();
DBObject dbObject = cursor.next();
row.put("created", dbObject.get("created"));
row.put("total", dbObject.get("total"));
row.put("userId", dbObject.get("userId"));
rows.add(row);
}$match = array(
'created' => array('$gt' =>
new MongoDate(strtotime('2014-06-01'))
));
$cursor = $transactions->find($match);
$rows = array();
while ( $cursor->hasNext() ) {
$dbObject = $cursor->getNext();
$rows[] = array(
'created' => $dbObject['created'],
'total' => $dbObject['total'],
'userId' => $dbObject['userId']
);
}All I've done here is remove the .get() call on the properties I didn't need. In fact, at this point, the database driver is still returning all of those properties; I'm just not accessing them. I wanted to see if that alone would make any difference. And in fact, it did. Hundreds of iterations of this code averaged in at 0.405 seconds. That's a 63% speed improvement. Of course the percentage makes it seem more grandiose than it really is, since that's only a 0.25 second improvement, which is not that big of a gain. But it is still an improvement, and it was consistent. Accessing fewer properties from the cursor results in a speed improvement. But while this sped things up a tiny bit, I knew that we could do better by forcing the database driver to stop returning the extraneous data, a la a project clause:
SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = f.parse("2014-06-01");
DBObject gt = new BasicDBObject("$gt", startDate);
DBObject match = new BasicDBObject("created", gt);
DBObject project = new BasicDBObject("total", true);
project.put("userId", true);
project.put("created", true);
Cursor cursor = transactions.find(match, project);
List<Map> rows = new ArrayList<>();
while ( cursor.hasNext() ) {
Map<String, Object> row = new HashMap<>();
DBObject dbObject = cursor.next();
row.put("created", dbObject.get("created"));
row.put("total", dbObject.get("total"));
row.put("userId", dbObject.get("userId"));
rows.add(row);
}$match = array(
'created' => array('$gt' =>
new MongoDate(strtotime('2014-06-01'))
));
$project = array(
'created' => true,
'total' => true,
'userId' => true
);
$cursor = $transactions->find($match, $project);
$rows = array();
while ( $cursor->hasNext() ) {
$dbObject = $cursor->getNext();
$rows[] = array(
'created' => $dbObject['created'],
'total' => $dbObject['total'],
'userId' => $dbObject['userId']
);
}This isn't much different than the last example. I'm still selecting only the data points I care about, but now I've added a project clause to the find() call. This means the database driver is no longer returning all the extraneous properties in the first place. The results? On average, this call took 0.029 seconds. That's a 2,186% speed increase over our original query. And that is worth paying attention to. While my last example wasn't all that telling, this one, on the other hand, confirms my hypothesis. If you only select the data you need, and none of the data you don't need, your queries will perform better. (This is true on any database platform.) The consequence of this is that you can't really use a general-purpose POJO for your collection -- not if you want your code to perform well, that is. Instead, you might have any number of contextual POJOs that access different parts of the same collection. It's a trade-off that may prove worth it for the sheer speed.
And I had one more test, just because I was curious. Up until now I've been using the find() command to grab my data, but Mongo also has another way of retrieving data: the aggregate pipeline. I remember reading somewhere that the AP actually spun up multiple threads, whereas a simple find() call was restricted to one. (Don't ask me for a source on that, I'm vaguely remembering heresay.) So I wanted to see if simply switching out those method calls would have any added bonus. Here's what I tried:
SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = f.parse("2014-06-01");
DBObject gt = new BasicDBObject("$gt", startDate);
DBObject match = new BasicDBObject("created", gt);
DBObject project = new BasicDBObject("total", true);
project.put("userId", true);
project.put("created", true);
AggregationOptions aggregationOptions = AggregationOptions.builder()
.batchSize(100)
.outputMode(AggregationOptions.OutputMode.CURSOR)
.allowDiskUse(true)
.build();
List<DBObject> pipeline = Arrays.asList(match, project);
Cursor cursor = transactions.aggregate(pipeline, aggregationOptions);
List<Map> rows = new ArrayList<>();
while ( cursor.hasNext() ) {
Map<String, Object> row = new HashMap<>();
DBObject dbObject = cursor.next();
row.put("created", dbObject.get("created"));
row.put("total", dbObject.get("total"));
row.put("userId", dbObject.get("userId"));
rows.add(row);
}$match = array(
'created' => array('$gt' =>
new MongoDate(strtotime('2014-06-01'))
));
$project = array(
'created' => true,
'total' => true,
'userId' => true
);
$pipeline = array(array('$match' => $match), array('$project' => $project));
$cursor = $transactions->aggregateCursor($pipeline);
$rows = array();
while ( $cursor->hasNext() ) {
$dbObject = $cursor->getNext();
$rows[] = array(
'created' => $dbObject['created'],
'total' => $dbObject['total'],
'userId' => $dbObject['userId']
);
}That test ran, on average, in 0.035 seconds. That's still a 1,794% speed increase over our first test, but it's actually 0.006 seconds slower than then last one. Of course a number that small is a negligible difference. But the fact that there is no difference is worth noting. There is no tangible benefit to using the aggregate pipeline, without a $group clause, versus an ordinary call to find(). So we'd might as well stick with find(), especially considering we weren't aggregating anything, anyway.
But now comes the question of how we go about getting data from other collections. That userId is effectively a foreign key, so we need to do additional queries to get that information. (Side note: you could just duplicate the relevant information instead of, or along with, the foreign key, since that's kind of the Mongo way. But what happens when a person changes their name? This is the problem with non-relational databases.)
The code that I had originally set out to improve did something that I immediately recognized as bad: it looped over the cursor on Transactions, and for each value, ran another query to the Users collection. I refer to these kind of queries as "one-off" queries, since that's kind of what they are. Let me show you some code to better explain what I mean.
SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = f.parse("2014-06-01");
DBObject gt = new BasicDBObject("$gt", startDate);
DBObject match = new BasicDBObject("created", gt);
DBObject project = new BasicDBObject("total", true);
project.put("userId", true);
project.put("created", true);
Cursor cursor = transactions.find(match, project);
List<Map> rows = new ArrayList<>();
while ( cursor.hasNext() ) {
Map<String, Object> row = new HashMap<>();
DBObject dbObject = cursor.next();
ObjectId userId = (ObjectId) dbObject.get("userId");
row.put("created", dbObject.get("created"));
row.put("total", dbObject.get("total"));
row.put("userId", userId);
// one-off query to the Users collection
DBObject userProject = new BasicDBObject("firstName", true);
userProject.put("lastName", true);
DBObject user = users.findOne(userId, userProject);
row.put("firstName", dbObject2.get("firstName"));
row.put("lastName", dbObject2.get("lastName"));
rows.add(row);
}$match = array(
'created' => array('$gt' =>
new MongoDate(strtotime('2014-06-01'))
));
$project = array(
'created' => true,
'total' => true,
'userId' => true
);
$cursor = $transactions->find($match, $project);
$rows = array();
while ( $cursor->hasNext() ) {
$dbObject = $cursor->getNext();
$userId = $cursor['userId'];
// one-off query to the Users collection
$userMatch = array('_id' => $userId);
$userProject = array(
'firstName' => true,
'lastName' => true
);
$user = $users->findOne($userMatch, $userProject);
$rows[] = array(
'created' => $dbObject['created'],
'total' => $dbObject['total'],
'userId' => $dbObject['userId'],
'firstName' => $user['firstName'],
'lastName' => $user['lastName']
);
}I can tell you that when I ran this code against my local instance of MongoDB, it took, on average, 0.319 seconds to run. That doesn't seem so bad at all, especially considering all it's doing. Again, this matches about 30,000 documents in the Transactions collection, and clearly we're making just as many calls to the Users collection. But while this seems fine on my local machine, that is not a realistic test. In real world circumstances, you would not have your database on the same server as your codebase. And even if you did, you won't forever. Inevitably you're going to need some code to run on a different server. So I re-ran the same tests using a remote instance of MongoDB. And that made a BIG difference. Suddenly this same little routine took 1709.182 seconds, on average. That's 28-and-a-half minutes. That is ridiculously bad. I will admit, though, that my wifi speed here at home is not the best. I re-ran the same test later, on a better network, and it performed at 829.917 seconds. That's still 14 minutes, which is dreadful.

Why would this simple operation take so long? And what can be done about it? Imagine this: let's say you went into the DMV office and needed to look up a bunch of records. You have a list of the records you need on a handy-dandy clipboard. So you stand in line, and once you're called to the desk, you ask the clerk, one by one, for the records on your clipboard. "Can you give me the details for Record A?" "Can you give me the details for Record B?" That's straight-forward enough, and will be efficient as it can be. But if the clerk you're talking to only has part of the data you need, and tells you you'll need to visit a different office to retrieve the other missing puzzle pieces, then it would be a bit slower.
If you're querying against your own local machine, it would go something like this:
- Ask Cleark A for Record 1
-
Clerk A gives you everything they have about Record 1
- Clerk A tells you to talk to Clerk B for the rest of the information
- Leave Clerk A's line, and stand in Clerk B's line
- Ask Clerk B for the rest of Record 1
- Clerk B gives you the rest of Record 1
- Leave Clerk B's line, and return to Clerk A's line
- Repeat for Record 2...
That doesn't seem very efficient, does it? But that's the trouble with non-relational databases; disparate collections are in different places. And keep in mind that this analogy actually represents the best case scenario, where Clerk A and Clerk B are in the same room. But that isn't realistic. A more realistic illustration would involve Clerk A at the DMV office, and Clerk B located a mile or two down the road, at the Social Security office. So for each record on your clipboard, you drive back and forth from the DMV to the Social Security office. You can see why it'd be so slow. That "drive" back and forth is called network latency.
But we can do better than that. What if, instead of driving back and forth for each record, you simply asked the clerk at the DMV for all the data they had all at once, and then afterwards you compiled a comprehensive list of all the records you'd need from the Social Security office? That way, you'd only have to make the drive over there once, rather than making 30,000 drives back and forth. In Mongo, you'd only be doing two calls to the database: one bulk call to the Transactions collection, and then a subsequent bulk call to the Users collection. Here's some code to illustrate:
SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = f.parse("2014-06-01");
DBObject gt = new BasicDBObject("$gt", startDate);
DBObject match = new BasicDBObject("created", gt);
DBObject project = new BasicDBObject("total", true);
project.put("userId", true);
project.put("created", true);
MongoJoinCache join = new MongoJoinCache();
Cursor cursor = transactions.find(match, project);
List<Map> rows = new ArrayList<>();
int i = 0;
while ( cursor.hasNext() ) {
Map<String, Object> row = new HashMap<>();
DBObject dbObject = cursor.next();
Object userId = (ObjectId) dbObject.get("userId");
row.put("created", dbObject.get("created"));
row.put("total", dbObject.get("total"));
row.put("userId", userId);
join.add(userId.toString(), i);
rows.add(row);
i++;
}
DBObject userMatch = join.resolveCache();
DBObject userProject = new BasicDBObject("firstName", true);
userProject.put("lastName", true);
cursor = users.find(userMatch, userProject);
while ( cursor.hasNext() ) {
DBObject dbObject = cursor.next();
Object userId = (ObjectId) dbObject.get("_id");
Set<Integer> indexes = join.get(userId.toString());
for (Integer index : indexes) {
Map<String, Object> row = rows.get(index);
row.put("firstName", dbObject.get("firstName"));
row.put("lastName", dbObject.get("lastName"));
rows.add(index, row);
}
}
public class MongoJoinCache {
private final Set<String> objectIds;
private final Map<String, Set<Integer>> objectToIndexMapping;
private int total = 0;
public MongoJoinCache() {
objectIds = new HashSet<>();
objectToIndexMapping = new HashMap<>();
}
public void add(String objectId, Integer index) {
objectIds.add(objectId);
Set<Integer> indexes;
if (objectToIndexMapping.containsKey(objectId)) {
indexes = objectToIndexMapping.get(objectId);
} else {
indexes = new HashSet<>();
}
indexes.add(index);
objectToIndexMapping.put(objectId, indexes);
total++;
}
public Set<Integer> get(String objectId) {
return objectToIndexMapping.get(objectId);
}
public Integer size() {
return total;
}
public DBObject resolveCache() {
if (size() == 0) {
return null;
}
final BasicDBList ids = new BasicDBList();
for (String id : objectIds) {
ids.add(new ObjectId(id));
}
DBObject match = new BasicDBObject("_id", new BasicDBObject("$in", ids));
return match;
}
}$match = array(
'created' => array('$gt' =>
new MongoDate(strtotime('2014-06-01'))
));
$project = array(
'created' => true,
'total' => true,
'userId' => true
);
$userIds = array();
$cursor = $transactions->find($match, $project);
$rows = array();
$i = 0;
while ( $cursor->hasNext() ) {
$dbObject = $cursor->getNext();
$userId = strval($dbObject['userId']);
$userIds[$userId][] = $i;
$rows[] = array(
'created' => $dbObject['created'],
'total' => $dbObject['total'],
'userId' => $dbObject['userId']
);
$i++;
}
$userMatch = array('_id' => array('$in' => array()));
foreach ( $userIds as $userId => $indexes ) {
$userMatch['_id']['$in'][] = $userId;
}
$userProject = array('firstName' => true, 'lastName' => true);
$cursor = $users->find($userMatch, $userProject);
while ( $cursor->hasNext() ) {
$dbObject = $cursor->getNext();
$userId = strval($dbObject['userId']);
foreach ( $indexes as $userIds[$userId] ) {
$rows[$index]['firstName'] = $dbObject['firstName'];
$rows[$index]['lastName'] = $dbObject['lastName'];
}
}Phew. That's a lot more code! Well, on the Java side anyway. (PHP arrays are awesome; Java people don't even understand.) But the million dollar question is whether there is any tangible benefit to all that extra code I just threw at you. Here are the results: When running against my local machine, this ran for an average of 0.339 seconds. Against the previously-mentioned 0.319 seconds on my local machine, this is slightly slower. So why bother with all this extra code if it's slower? Because that's not really a fair test. The difference of 10 milliseconds is negligible, but more importantly, there is no universe in which you can reliably expect to have zero network latency. There will always be network latency in production environments. So a real test is against a remote instance.
So what happens when I ran this code against a remote MongoDB server? Remember that it took 28 ½ minutes before. With this code shown above, however, on average, it ran in 6.191 seconds. You read that correctly. That is an astronomical speed improvement of 27,508%. And even if your network latency isn't as bad as mine was (and it shouldn't be), you can still see nonetheless that this method will always be faster, by an order of magnitude.
If you think about it, it makes sense. We took a query which had been O(n²) in complexity and reduced it down to O(2n) -- at most. In fact, it's probably less than that in practice, since there are bound to be duplicate foreign keys. I'm guessing that the developers of relational databases do something exactly like this, under-the-hood in their database code. In order to join two tables, they probably first have to collect all the foreign keys from the first table into a set, and then grab the corresponding rows en masse from the second table. The big difference is that with SQL, you don't have to think about any of this. You just type INNER JOIN and bam, it's all magically done for you. But because Mongo doesn't include this as a concept, you have to write your own database wrapper code in order to be able to use it efficiently.
So what's the takeaway from all of this? First, you can write your own wrapper code to effectively perform a join operation in Mongo, and doing so is hugely advantageous in terms of speed, albeit slightly annoying. But it's vital to your success if you're going to use Mongo. Secondly, what I hope is the bigger takeaway is that you shouldn't have to. Like I've been saying all along, if you have to resort to writing what is essentially your own low-level database code, it's a sure sign that you're using the wrong database. If you've read this far, that means you should probably just use SQL.
TL;DR
To conclude, here are the more practical takeaways broken down:
-
Only select the data you absolutely need, and nothing more
- Use a project clause to limit your data
- Don't instantiate general purpose objects with every property
- Don't do one-off queries inside of loops!
- Minimize network latency by grabbing batches
And that is how you do a "Join" in Mongo.
MongoDB or: How I Learned to Stop Worrying and Love the Database
I come from a SQL background. For seven years, the primary database I worked with was Microsoft SQL Server. I did a little bit of work in MySQL occassionally as well, but in either case, I definitely came from the school of thought that SQL is the only way to store data. This is not without good reason. SQL is powerful. SQL is well-maintained and well-supported. SQL is stable and guarantees data integrity. And SQL is fast, when you know how to use it.
Since transitioning to a new job, though, I found myself flung into a strange new world: the world of NoSQL databases (aka document-oriented databases). In particular, a database called MongoDB. More on that in a second.
When it comes to programming, I consider myself a person who is more interested in solving problems than strict academic purity. With that said, I do tend to be obnoxiously meticulous with my code, but I would much rather throw out the super-careful attention to detail and just get something done, and subsequently tidy up/refactor the code, if it really comes down to it. And I think it is this desire to get something done that has really increased my appreciation for Mongo. Although it is not without its pitfalls, and it is definitely not the right choice in a lot of situations. However, I've been discovering that it is the right choice in a few situations where SQL is not.

My initial reaction to using Mongo was one of disgust. Reading through the design patterns, it seemed like it encouraged huge duplication of data, restricted or impaired your access to the data, and didn't handle date-math very well at all. Unfortunately, all three of those initial impressions are true. But that doesn't mean you shouldn't use it. I won't get into the document-style approach to data because you can already find plenty of material on that yourself. It does involve duplicating data, which would otherwise just get joined in SQL. And that leads into the next point: there are no JOINs in Mongo. They do not exist; you can only query one table at a time. This is what I meant by restricting your access to data. But actually, as I've been learning, this really won't slow you down if you understand Big O notation and how to write Mongo queries effectively. And lastly, all dates in Mongo are stored in UTC time, no matter what. Mongo offers a way to group by dates, but no good way to transform that data into different timezones before grouping it. Which means your data is probably off by 5 hours.
With those downsides out of the way, let me explain why it's actually pretty cool. One of the applications I worked on at my last job was something called "Form Builder." It was actually a pretty slick application that let you create "forms." Forms could have multiple pages, and each page could have multiple questions. In other words, think Wufoo, but without all the pretty graphics. I created a few tables in SQL to build this: one for the forms themselves, another for the pages contained within those forms, a third for the questions on each page, and then one for receiving answers from users. Of course there are more tables involved than just these four, but you get the basic idea.
The "questions" table contained, among other things, the text of the question itself, an ENUM question type (represented in data as a TINYINT), and a number of different fields such as the maximum number of characters a user might enter. In the end, we came up with probably about 20 different question types, ranging from text input, to multiple choice as a drop down menu, multiple choice as radio buttons, multi-line text, asking the user to upload an image, asking the user to upload a file, a preformatted block of address fields, an email field... the list goes on. The point is, with all these disparate types of questions, each one is going to be configured slightly differently. It makes sense to limit the number of characters for text inputs. It doesn't make sense to limit the characters when it's a dropdown menu, however. It makes sense to configure an allowed list of file extensions when you're asking the user to upload a file, but not when they don't. It makes sense to configure a list of multiple choice options when you're asking a multiple choice question, but not otherwise.
What this means, when designing a database table in SQL, is that you really have two choices. Either you can have a bunch of columns that are sometimes relevant, depending on the particular row, or you can sort of abuse SQL by having some "general purpose" columns that get re-used for different purposes. These types of columns are usually either VARCHAR(8000) or TEXT, and they're considered bad practice by DBAs because you are essentially forfeiting the power of SQL by storing it in a different way. I ended up doing a mix of the two.
Here's a snapshot of the questions table:

As you can see, there's a character limit column on every field, even though not every field actually enforces a character limit. But then there's also this column called extra_info which looks like it contains a bunch of gobbledygook. That's really just a serialized PHP array, which is kind of like JSON, but not as elegant. (It predates JSON.) It's a way of storing any amount of arbitrary information in a quickly-usable-in-code format. Within SQL, storing data that way is a black box. There is no way to search it, but you store it that way because you don't need to search for it; you only need to access it. Lots of people do this, but it is considered an abuse of the database, because you're no longer really using the database.
What I didn't realize at the time, was that there was a different way of thinking about this problem entirely. This type of project was an absolutely perfect candidate for using Mongo, and I'll tell you why.
Mongo has different nomenclature than SQL. "Collections" are the equivalent of tables, "documents" are the equivalent of rows, and "fields" are the equivalent of columns. Every document in a collection is simply a JSON object. And a collection does not have any defined structure to it whatsoever. You read that correctly. It has no structure. There are no column definitions. One row in the table may have an entirely different set of columns than the next row. They're just arbitrary documents. It's all up to you. If you want one row to have one set of columns, fine. The documents are whatever you tell you them to be. They don't really care about each other.
With that said, you will end up having most of the same columns present on every document within a given collection, because otherwise there would be no point. But in Mongo, I could represent the same "questions" table above like this:
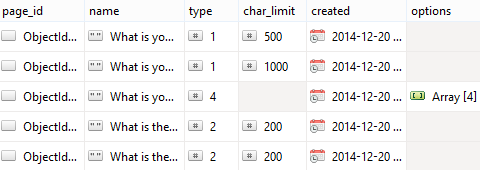
So you see here, one row doesn't enforce a character limit, so the field isn't present at all. Another row has an options array, whereas the rest don't have that column present in the first place. The difference between this and SQL is huge. In SQL, you can accomplish the same thing as I described above, but you cut off your own access to the data in the process. Mongo on the other hand is designed for this.
In Mongo, I could run a query like this, to find all the questions that have a character limit:
Or I could run a query like this, which will locate any questions that have an options array present, with one of those options being the word Red:
Mongo queries themselves are an off-shoot of JavaScript, which means you can use regular expressions too, which is awesome. (Although those are better suited for ad-hoc queries than actual production ones.)
From one SQL programmer to another, I would recommend giving Mongo a try. It has its annoyances, believe me. But after using it, you start to realize that SQL does too, and the realization that SQL isn't the only approach to anything and everything can be eye-opening. Having more tools in the toolbox helps make you a better programmer. Understanding when to use them, and when not to use them, is key as well. But I have to say, it's worth giving it a shot. I think you'll find there are some applications where it actually is better suited.
And by the way, if you're going to use MongoDB, you are going to need a client to access it as well. The one I've been using, the one that is pictured in the screenshot above, and the one that is hands down the best out there, is called Robomongo. The screenshot shows one of three possible ways of viewing the data (in tabular format). But it also lets you view documents in a hierarchical list, or as straight JSON text.
Programming is like salsa dancing, for better or worse
My last post was about programming, and this one will be too. Although the last one was a "how to" post, whereas this will be philosophical musings on the merits of programming languages. So with that said, let me tell you that I hate Java. (I'm not referring to coffee, as my hatred of that flavor is merely incidental.) But Java, as a programming language, is dreadful. Why? Because of something that has nothing to do with the actual language at all.
I will posit to you that all modern programming languages (worth discussing in terms of business applications) are basically the same. Any major programming language worth its salt is going to have things like exception handling, regular expressions, loop structures, object orientation, etc. Each one will naturally have different syntax and their own unique quirks, but it all comes out in the wash. If you've been programming for any amount of time, you probably won't have too much difficulty jumping from one major language to another.
What really sets languages apart, then, is how easy they are to pick up when you don't know what you're doing. There are three facets to this. Easy to pick up languages should have (1) as little boilerplate as possible, (2) a low probability of causing fatal errors, and (3) good documentation. Java fails miserably on all three counts. Java is riddled with meaningless and cryptic boilerplate. And unless you type everything exactly right the first time, your Java program will not compile. You'll very likely be given some obscure red error message.
And on documentation -- perhaps I'm just spoiled as a PHP developer, because PHP, hands down, has the best documentation out there of any language. The PHP manual is pretty, it's full of helpful and real-world examples, and the user comments are renowned for their usefulness. Sure, every once in awhile you'll get a bad egg in there, but overall, PHP's user comments are so highly regarded that you can actually download an official copy of the manual with user comments included.
Java, on the other hand, has miserable documentation. It's not as though things go undocumented in the Java world. On the contrary -- every single class, method, and property in Java is documented, and that documentation is verbose. But those documents say nothing. Their length is downright deceiving, as it's often some of the most obscure language you'll ever run into. And don't expect to find any use case examples or user comments.

Now here's the analogy you've all been waiting for. I've taken salsa dance classes a couple of times over the years. I'm not exceptional at it, but the classes are fun. But I've learned the hard way that what you learn in the classroom is very different from actually going to a club and dancing real salsa with strangers. I had a bad experience with that last year; a friend (who is a girl) needed someone to go with her to a salsa dance downtown. It might be the bitterness talking here, but I think girls have a very different experience going to dances than guys do -- particularly guys who aren't great dancers and only have a lukewarm interest in it. More on that in a moment.
Looking at all the other dancers there was intimidating. I quickly realized just how little the classroom had taught me. Add to that my natural resistance to talking to strangers / fear of rejection, and the scene seemed downright hellish.
I was able to approach one girl who seemed closer to my own lack of expertise, and she was graciously willing to lend herself to me for one dance. But it became quite clear, less than halfway through the song, that I had run out of moves and didn't really know what I was doing. So after the song ended, she politely moved on to the more experienced dancers who were ready and willing to lead her, spin her, and dazzle her. That process taught me literally nothing -- besides the striking realization that I am not a talented salsa dancer. It was pretty discouraging and left me with little desire to ever go back (at least until I miraculously transform into a great, confident dancer with an endless repertoire of moves).
From what I've seen, experimenting with Java programming is a lot like that. If you aren't already an exceptionally talented and attractive programmer, no one's going to help you. The documentation sure won't. Or even if you do "get a dance" (i.e. you get some very simple piece of code to compile), you probably won't learn very much from it, and you certainly won't be made to feel very welcome. The learning curve is just too damn intense.
Whereas, my friend's perspective of going to a salsa dance club (as a girl) is probably a lot more akin to trying out PHP programming. In that case, all sorts of guys will probably come up to you, ask you to dance, and lead you on exactly how you should move. As long as you understand the basics, you'll do fine. That's PHP's documentation, in a nutshell. And if you make a mistake on the dance floor (or in your code), people will probably just laugh it off and tell you you're great anyway (or, your program will still run and the output will still be pretty close to what you're expecting).
Different programming languages fulfill different niches, some compete more directly with each other than others, and every language has its quirks. But at the end of the day, what really matters is how easy it is for newcomers to get on-board. In that regard, PHP does exceptionally well, while Java crashes and burns and dies a hundred fiery deaths.
Java is a discouraging language, mainly because of its poor documentation. I think most programming languages would be benefited by having the humility to admit just how much of a better job PHP does when it comes to documentation, and if they learned to model their own off of that. Languages borrow from each other all the time. And if languages like Java could start to borrow that from PHP, everyone would win.
Agree? Disagree? I'd love to hear from you in the comments. And if you'd like to read more on why PHP is actually pretty great, check out this article by Nikita Popov.
How to Sign a Java Applet
I am not a Java developer. I'm a PHP developer who happens to have written a Java applet in NetBeans. (Apparently it's not technically an applet, but a "Web Start application;" I don't know what the difference is and I don't care.) For a long time my applet was "self-signed," until Java changed their policy last year, no longer allowing self-signed applications after a certain cutoff date. That meant I started seeing nasty warnings like this:
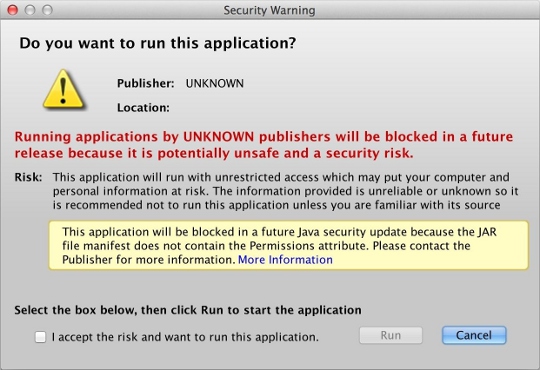
...which eventually changed into this:
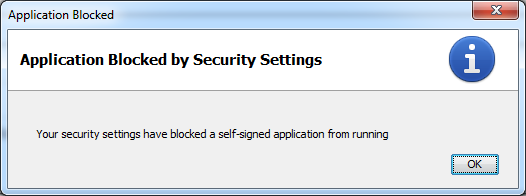
So I had to purchase a Code Signing certificate from some signing authority like GoDaddy or Thawte or Comodo. I went with GoDaddy. What I learned along the way is that Java developers are the worst kind of developers when it comes to documentation. They do have a lot of documentation, but it's totally useless. They have 10,000 word articles that effectively say nothing at all. Unless you already understand everything and don't need to be reading documentation in the first place, it's virtually impossible to figure out how anything works. So this blog post is an effort to offer up what I learned along the way while trying to sign my Java applet, from and for the developer who knows nothing about Java boilerplate.
After purchasing the certificate from GoDaddy and trying, for hours, to make two cents of their installation instructions, here's what I learned: you have to use Firefox to install your certificate. I don't know why; I don't care why; you have to do it. Their tech support technician had me navigate to certs.godaddy.com, where I had to install the Code Signing Certificate into Firefox. Originally I had tried to download a "backup copy" of the certificate directly. It gave me a choice of a DER file (actually an SPC file) or a PEM file. But these files will not work. Apparently these files save the certificate in PKCS#7 format, which isn't good enough for some reason. You need a file in PKCS#12 format, which requires you install it into Firefox and then use Firefox to export the file. (Why you can't just download that file directly, I do not know.) So I had to re-key my certificate, install it into Firefox, and then go to Tools > Options > Advanced > View Certificates.
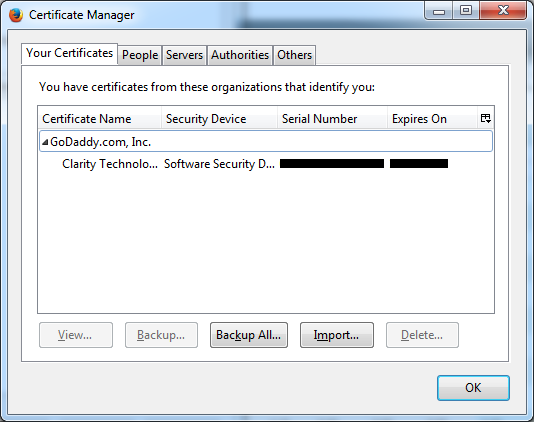
From there I located the certificate (pictured above), clicked "Backup..." which let me save it in PKCS#12 format, as a P12 file. Apparently this is also called the PFX format.
In the GoDaddy installation instructions, I had been trying to use their "Approach #1" to install the certificate, when I originally downloaded the PEM file. As far as I can tell, this approach is a wild-goose chase. I would move the PEM file into my Java directory, open up a command prompt in the same folder, and then try this command:
| Informational Only - Ignore This Part |
|---|
| > keytool -import -trustcacerts -keystore NewKeystoreFile.jks -storepass myPassWord -alias MyAlias -file cert.pem |
That would generate a file called NewKeystoreFile.jks in that same directory. Then I would go into NetBeans (which I used to build my applet), select Project Properties, go to Application > Web Start > Signing > Customize, and plug in that file:
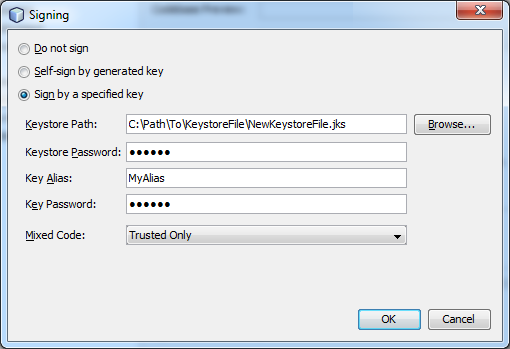
But when I did a Clean & Build, my applet would not compile, and I would receive the following error:
jarsigner: Certificate chain not found for MyAlias. MyAlias must reference a valid KeyStore key entry containing a private key and corresponding public key certificate chain.
Apparently the PEM file (PKCS#7 format) doesn't cut it. It installs the certificate, but not the private key, into the keystore. I don't know what that means, but what it means is that it's broken and my applet won't work. So instead, I had to use the aforementioned P12 file I got from Firefox. There are no instructions on how to do this in GoDaddy's documentation. I was fortunate enough to discover a set of instructions provided in a blog post by someone from a company called JAMF Software. I don't know who they are but that blog post was a godsend.
So I copied my cert.p12 file into my Java directory, opened up a command prompt in the same folder, and used this command:
> keytool -v -list -storetype pkcs12 -keystore cert.p12
That command doesn't actually do anything, other than print out lots of information about the cert.p12 file on the screen. The only purpose of running that command is to find out what alias name GoDaddy decided to use in their certificate. In my case, because I work for Clarity Technology Group, GoDaddy used the following obnoxiously long alias name:
clarity technology group, inc.'s godaddy.com, inc. id
Whatever your alias happens to be, you need it for the very next step, which is why you run that first command to determine what it is. And if it's got spaces and apostrophes, etc. like mine did, you'll need to encapsulate it in double quotes. The next command, which is the crux of this whole process, is this:
> keytool -importkeystore -srckeystore cert.p12 -srcstoretype pkcs12 -srcalias "clarity technology group, inc.'s godaddy.com inc. id" -destkeystore NewKeystoreFile.jks -deststoretype jks -deststorepass myPassWord -destalias MyAlias
That generates a file in that same directory called NewKeystoreFile.jks, which you can then move out to some other directory and plug into NetBeans as shown above. And then it should actually work! I was able to do a Clean & Build without any error messages. And now, when I load up my applet, the popup message looks like this:
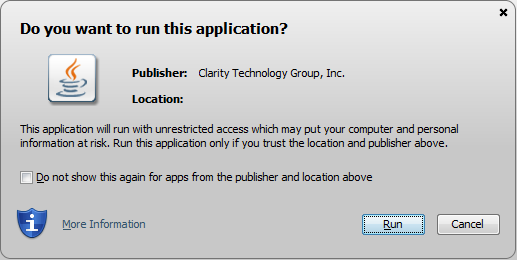
I'm going to write a later blog post about how annoying Java is. I am annoyed. Stay tuned.
Programming
I program to create
To express intelligence and beauty in a way that no one understands
Not no one, but those who do understand are too busy creating their own works of art to ever stop and admire the grace and form and color of others
But that's OK
Programming isn't a major sporting event
It doesn't lend itself well to advertising agencies, interrupting every 20 seconds to break for commercial
Good programming is quiet
Good programming doesn't boast
It is intelligence and a reward in itself
Applause and fame aren't needed
Programming is like building the greatest and most elaborate Lego fortress you ever dreamt up as a kid, with slightly more interactive Legos
And you don't have to scream every time you step on one
Programming is the same thrill an extrovert gets from exploring good conversation in a brand new language
Programming languages are new worlds to explore,
each one tracing the footsteps of those who came before and what brought them there
Programming is having a constant fight with someone who refuses to listen
But actually coming out on top for once
It is kicking and screaming and gnashing and gnawing until the damn thing finally works
Maybe it is like stepping on a Lego
But what you don't realize is that what really yields in the process is always you,
leaving you better equipped for the next challenge
Programming is growth
Programming is problem-solving art in worlds that the world doesn't see
Programming is an escape from the world
Programming is an avoidance of society because programming is better than society
Programming is controlled and stable;
you only get out what you put in and if anything goes wrong there's a stack trace subpoena to show you who's the culprit and how to convict him
Programming doesn't believe in the random or unexplained
Programming is safe
Programming is reliable
Programming lets you explore the depths of art and soul
But it doesn't get you laid like art students
Does pay the bills though, unlike art students
But the kind of programming that is truly thrilling is always off the clock
Programming is an addiction in the best sort of way
Programming is staying up till 4:00 because you want to, because you can't put it down, because you have to make it perfect, absolutely beautiful
Programming is learning, learning, learning, learning; you never stop learning
Programming is lust for knowledge and structure and purity
Programming is expression in a way the world never sees quite right
And so I keep programming
Who needs the world anyway
That's not a very good ending
I'll fix it in the next release
Fun with QR codes
Lately I've been a little bit addicted to QR codes, ever since installing a Barcode Scanner app for my phone. They are so cool! But they're also becoming a bit ubiquitous, as you see them on all sorts of fliers and posters and even postcards now, and so we're starting to tune them out mentally as the novelty fades. As a result, marketing people are looking for ways to make them more eye-catching, and one such way is by arbitrarily inserting other graphics into them that look nothing like QR codes.
Someone discovered/realized that it is possible to actually remove whole portions of the QR code and replace them with pretty much whatever you want, just because a lot of the data that is encoded in QR codes is not actually the data itself, but large amounts of "error correcting." The original designers of QR codes were smart enough to make them in such a way that even if you were missing part of it, it could still work. So marketing people, and now myself as well, have already begun to abuse that fact by ripping out the middle of QR codes and putting other stuff there instead. For example, here's a functioning code that will take you to my website, and also happens to include my initials.

In this case, the graphics I inserted actually do resemble part of the QR code itself. And I like that. I think it's more subtle and gets people to raise an eyebrow. So last night I built a little utility to generate these and have included it below for mass consumption. Basically all I am doing is using a library called PHP QR Code to generate the initial image, then arbitrarily removing the center and drawing text on top of it. It was a bit tedious to develop, as the default PHP text function actually drew things larger than I was hoping for. So I wrote a function that draws the letters myself, pixel by pixel. (Not difficult at all, just tedious.)
I think seeing text in the middle of the code is cool enough that people might look at it and say, "wait... does that really work?" and then scan it out of curiosity. I realize, too, that by sharing this information with the world, I am only speeding up the rate at which the novelty of that wears off too, but it's going to wear off sooner or later anyway, and for now it is still kind of fun. So feel free to start generating your own QR codes using the little utility I hacked together last night!
A few words of caution: I am literally just removing the center and replacing it with whatever text you enter. There is no fancy calculation involved, it's just quick-and-dirty replacing the middle and hoping for the best -- which means that if you enter too much text, it might not work. It's better to minimize the amount of data removed, because the more you remove the less likely it is to work. And I've found that using longer URLs is actually better than using shorter URLs, because the longer ones require more space to generate so you end up with a smaller text footprint. And also keep in mind that each generation is unique, so if you leave the "direct download" box UN-checked and then just keep hitting refresh, you'll see the little dots change each time. Sometimes one combination won't work, while another one will for the exact same input. So just make sure to test it.